Optimize GitHub Actions for UI Builds and Tests with Cache
Published on .
#automation #CI #devflow #GatsbyJs #github actions #npm #tech
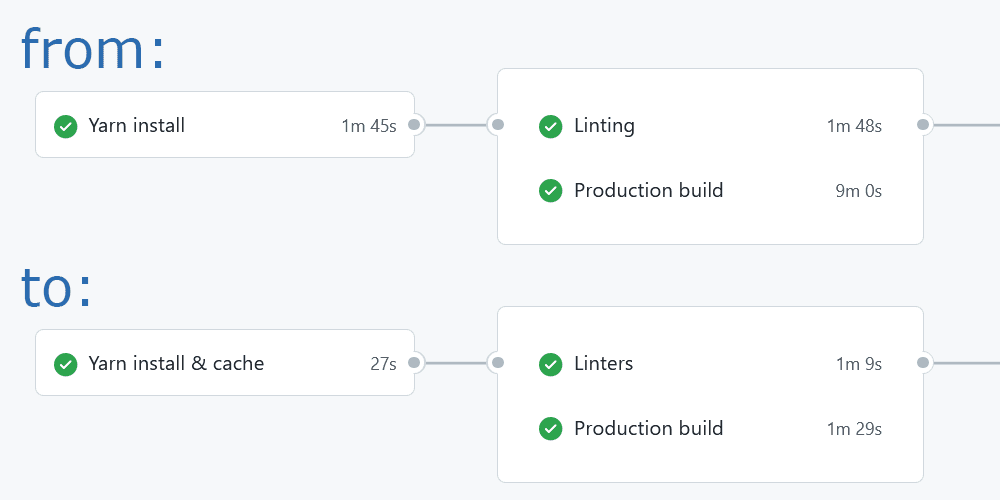
This blog is very new and quite empty (less than 20 pages) and yet I was experiencing 10 minutes long production builds on my local machine. And GitHub actions (which execute the production build at some point) were taking anywhere from 14 to 20 minutes.
Which is too long of a wait for a website preview deployed or pull requests verified. I decided to figure out what can be optimized and ended up with 6 to 10 minutes GitHub action runs. In this post I’d like to share my learnings. Hopefully it can help you to reduce the caffeine consumption while waiting for PR to get verified by linters or website to go live.
GitHub Action Terms
First, few notes on GitHub action terms and debugging options. If you are familiar with them feel free to head straight to optimization techniques.
Workflow is the whole yaml file describing events triggering it and list of jobs performed once it is triggered.
Workflow jobs run on different nodes (containers) in parallel, unless you explicitly define
relations between them with job.needs property.
Every job contains a list of steps which are executed on the same node sequentially.
Because of the independent nature of jobs execution, state of the working directory
is not shared between different jobs of a single workflow.
That’s why pretty much every job starts with checking out the branch with
uses: actions/checkout@v2 action.
Debugging GitHub Actions
Even though verifying GitHub action workflow locally is not possible and working on it
requires trial-and-error iterations there is an ACTIONS_RUNNER_DEBUG
environment flag
which makes this process a little easier.
In relation to caching, debugging flag helps us to see what keys are used for the exact and/or partial match and what kind of cache hit (if any) happened during the workflow run.
Dependency Cache vs Artifacts
GitHub provides two similar but distinct options for sharing files between workflows and workflow jobs: artifacts and dependency caching.
Artifacts are better suited for exporting something out of the CI pipe (i.e. to the external logging or analytics system) and have more restrictive storage limits. Also, artifacts are “scoped” by the workflow, while dependency cache is not.
We will be using dependency caching since we don’t need workflow scoping nor plan to make our cache public and can totally enjoy 10Gb of free storage we don’t need to manage in any way.
GitHub Dependency Cache Branch Scope
By design dependency cache is scoped within the branch originating the event triggering the workflow. At the same time, workflows triggered of any branch have read access to cache records of respective base (when applicable) and master branches.
This is important case you might see cache misses once PR is merged into the master branch even though minutes ago pull request update workflow had successfully built cache for it on the feature branch.
This is similar to variables scoping in programming languages where inner functions have access to parent function and global scope variables but not the other way around.
Dependency Cache Keys
Recommended actions/cache requires you to set the key for the exact cache hit.
Using the optional restore-key field allows you to start with the older cache version
(whenever it makes sense) and then, after updating cache with your application logic
(i.e. yarn install), save it with the exact key you were looking for in the first place.
This approach works very well when storing npm package manager cache folder, node_modules and also for incremental GatsbyJS production builds.
Please note that while key field takes the whole string, restore-keys takes a list
of key prefixes and they are used as such during the cache matching process.
More on cache key matching.
Last thing to note is that between multiple partial matches for any given key prefix, the newest cache record will be selected.
Caching Node Modules
Disclaimer: I’m using yarn 1.x as my package manager but similar optimization approaches should be applicable to npm.
Caching Package Manager Cache Folder
Recommended approach to caching npm dependencies is to cache package manager cache folder
(~/.cache/yarn or ~/.npm/_cacache) rather than project’s own node_modules.
That implies executing yarn install --prefer-offline to get dependencies copied from
the local cache into the node_modules folder whenever you need them.
I used this approach from the day one, and could see that even though dependencies
are indeed being copied from the local cache yarn install takes about a minute on
every step of the workflow.
If your workflow has four jobs and each of them requires node_modules folder to operate, four minutes will be spent on copying npm dependencies from one local folder to another.
Recommended actions/setup-node action is
using this approach and lock-file hash as an exact match key.
Caching node_modules Folder
I tried caching node_modules folder itself.
With that yarn install can be executed only once per workflow run — by the initial
setup job and only when exact cache hit didn’t happen.
All subsequent jobs (and even workflow runs) will be restoring exact node_modules folder
from the dependency cache using the exact key match.
Apparently restoring node_modules from cache is two times faster than copying files from package manager cache and takes about 30 seconds (per job). 2 minutes saved right there!
On the flip side — whenever lock-file is updated yarn install seems to remove all
the content of node_modules folder (if restored from the partial cache match) and download
all the dependencies (rather than just updated ones) over the network.
Basically for dependency update scenario caching node_modules doesn’t help at all.
At least not with yarn 1.x! Curious if npm behavior is different.
For me “regular” updates when yarn.lock file isn’t changed were a priority and
that’s what I was optimizing for.
Here is the code snippet I’m using to set up node_modules caching:
- name: node_modules cache id: node-modules-cache uses: actions/cache@v2 env: cache-name: node-modules-yarn cache-fingerprint: ${{ env.node-version }}-${{ hashFiles('yarn.lock') }} with: path: node_modules key: ${{ runner.os }}-${{ env.cache-name }}-${{ env.cache-fingerprint }} restore-keys: ${{ runner.os }}-${{ env.cache-name }} - name: Yarn install # called at most once for the workflow by the "setup" job if: steps.node-modules-cache.outputs.cache-hit != 'true' run: yarn install --prefer-offline --frozen-lockfileyaml
I’m setting node-version manually in yaml file as a
workflow scope environment variable.
Mainly to make sure I’m running particular node version
for all of my scripts.
But it also helps me to invalidate all existent caches by updating the value of the variable,
i.e. from 14 to 14.18 and vice versa.
Caching Both: Node Modules and Yarn Cache
I tried to optimize package-lock file update scenario by caching package manager…
cache along with node_modules, but it didn’t work.
Downloading and uploading lots of files from the folder actually made the yarn install
run slower than downloading all the dependencies over the network!
You can check my failed approach here.
Incremental GatsbyJs Builds
Similar to node_modules we can cache GatsbyJS production build artifacts.
I believe starting with version 3 GatsbyJs supports incremental builds out of the box —
no configuration necessary.
The only requirement is to maintain .cache and public folders between builds.
GatsbyJs build script will invalidate and update these folders for us. Thanks, Gatsby team, this is pretty cool and very helpful!
All we need to do is to configure caching for aforementioned folders:
name: Cache production build id: prod-build-cache uses: actions/cache@v2 env: cache-name: prod-build # most sensitive files from the build caching perspective key-1: >- ${{ hashFiles('gatsby-config.mjs','gatsby-node.ts','gatsby-ssr.tsx') }}- ${{ hashFiles('src/html.tsx','src/gatsby-hooks/*.*') }} # less impactful changes but important enough to make them part of the key key-2: ${{ env.node-version }}-${{ hashFiles('yarn.lock') }} with: path: | public .cache key: |- ${{ runner.os }}-${{ env.cache-name }}-${{ env.key-1 }}-${{ env.key-2 }}-${{ github.sha }} restore-keys: |- ${{ runner.os }}-${{ env.cache-name }}-${{ env.key-1 }}-${{ env.key-2 }}- ${{ runner.os }}-${{ env.cache-name }}-${{ env.key-1 }}-yaml
In my workflow Production build and Deploy are two separate (albeit sequential) jobs.
That’s why I’m storing commit specific (github.sha) version of the production build.
To increase the cache key specificity (and with that — quality of the partial cache match)
I’m using hashFiles of GatsbyJS configuration files and application level components.
We could totally get away with just ${{ runner.os }}-${{ env.cache-name }}-${{ github.sha }}.
Also, sometimes GatsbyJs doesn’t do a great job of cache invalidation, and I’m practically doing it
myself to be on the safe side.
That’s why you don’t see ${{ runner.os }}-${{ env.cache-name }}- being used as restore-key
option — I do want so start from scratch whenever gatsby config files change.
On average incremental builds reduced production build times from ten to three minutes. That’s three to four times faster than it was! With just ten lines of code and no need to dive deep into intricacies of Gatsby’s build process. Wow!
Conclusion
Using dependency cache for GitHub actions is fairly straightforward and, even though not without catches, can significantly reduce workflow running times with a few lines of yaml.
For now, I’m very satisfied with results of this optimization as well as overall workflow run times.
Wishing you the same and please let me know if you have any questions or comments.
References
- This website workflow using optimizations described
- GitHub actions basics
- Exhaustive GitHub actions syntax
- Improving GatsbyJs build performance on GatsbyJs docs